There is unanimous agreement in industry that the “fastest-moving” SKUs should be stored in the most convenient locations. Unfortunately, both engineering literature and practice disagree on what these terms mean. To be precise each must be based on an explicitly model. First: What is a “convenient” location?
Convenient storage locations
Consider the warehouse of Figure 6.9. Assume that the receiving doors are distributed across the lower edge of the warehouse and the shipping doors are along the upper edge. In this simplest model, a trailer may be parked at any door and so we assume the average location of receiving or shipping is the center location on the dock.
Now each time a pallet is stored at a particular location, the following variable labor costs will be incurred: Travel from receiving dock to location; and, later, travel from location to shipping dock. Therefore with each location i is associated a labor cost incurred by its use. (This labor cost is proportional to the distance di from receiving to location to shipping and so we may, without loss of generality, discuss convenience in terms of distance.) In a unit-load warehouse this cost is independent of what is stored in other locations and so, if location i is visited ni
times during the year, the annual labor cost will be proportional to

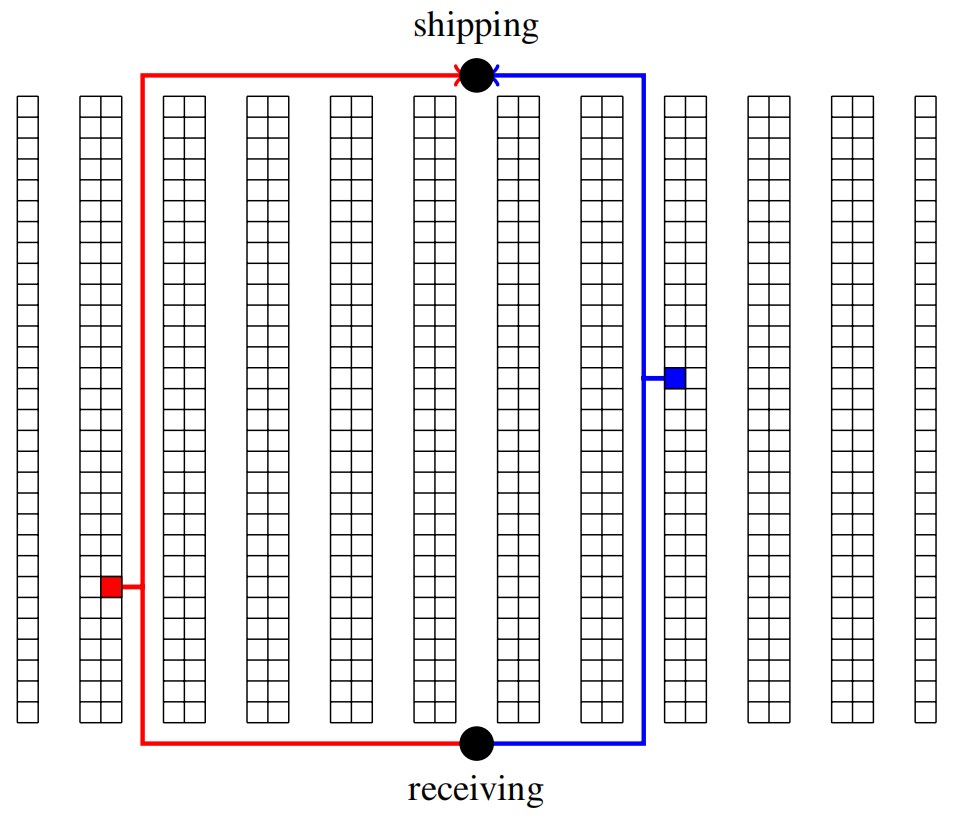
Figure 6.9: The blue location (right) is more convenient than the red location (left) because the total distance from receiving to the location, and from there to shipping is smaller.
Distances di are determined by the layout of the warehouse and are not easily changed. But frequencies of visit ni are determined by customer orders and by our choices of what to store where. By storing the pallets carefully, we can ensure that the most frequently visited locations are those of greatest convenience (smallest total travel di), thereby minimizing Expression 6.7.
Fast-moving SKUs versus fast-moving pallets
From the expression 6.7 for the labor cost of a location we prefer that SKUs with a lot of movement per storage location be stored in the best locations. In other words, we want to identify those SKUs that generate the most frequent visits per storage location.
In steady state, during a fixed interval of time
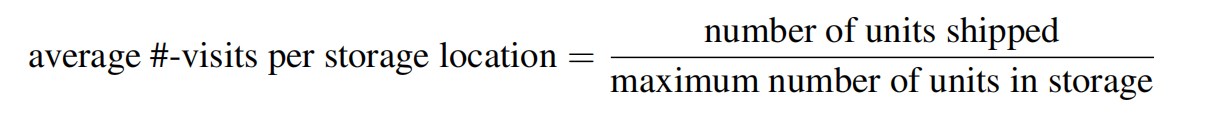
Thus, for example, a SKU that is received in order quantity 5 pallets and that sold 20 pallets last year would have generated about 20/5 = 4 visits per pallet location, which is more than a SKU that moved 100 pallets but was received in quantity 50.
So to minimize labor costs:
• Rank all the available pallet positions of the warehouse from least distance di
to greatest distance.
• Rank all SKUs from most to least turns.
• Move down the list, assigning the pallets of the next fastest-turning SKUs to the next best locations available.
This analysis is based on a warehouse that is operating at approximately steady state. What if the system is far from steady state? We can still approximate our intuition that the busiest SKUs belong in the most convenient locations; only now we must adopt a more detailed view that considers the rate at which individual pallets turn (not just SKUs). Now we choose that particular pallet that will be leaving soonest to be stored in the best location. So to minimize labor costs:
• Rank all the pallet positions of the warehouse from least distance di
to greatest distance.
• Rank all pallets from soonest departure to latest departure.
• Move down the list, assigning the next pallet to the next best available location.
阅读全文
收起全文
